

{kind=link}
# Entry
Line-by-line iteration is one of the most common performance bottlenecks in programs pandas code. This goes unnoticed when dealing with diminutive data sets, but when processing gigantic data sets it becomes vital.
panda is built on a mountain NumPywhich performs operations on entire arrays at once using compiled C code. Python’s line-to-line loop bypasses this entirely and forces each operation back to the Python interpreter, line by line.
This article discusses 7 alternatives to loops in pandas, each of which lends itself to a different type of transformation. At the end, you will have a clear mental map of which tool to reach for depending on the shape of the problem.
You can download Colab Notebook on GitHub.
# Configuring the sample dataset
Throughout this article, we will employ a realistic e-commerce ordering dataset:
import pandas as pd
import numpy as np
np.random.seed(42)
n = 100_000
categories = ['Electronics', 'Clothing', 'Home & Kitchen', 'Sports', 'Books']
regions = ['North', 'South', 'East', 'West']
df = pd.DataFrame({
'order_id': range(1, n + 1),
'customer_age': np.random.randint(18, 70, n),
'product_category': np.random.choice(categories, n),
'region': np.random.choice(regions, n),
'price': np.round(np.random.uniform(5.0, 500.0, n), 2),
'quantity': np.random.randint(1, 10, n),
'days_to_ship': np.random.randint(1, 14, n),
})
display(df.head())Exit:
We now have a dataset of 100,000 rows to work with.
# 1. The employ of vectorized operations in arithmetic
For any arithmetic or column comparison vectorized operations should be your first instinct.
What we want to do: Calculation of total revenue per order.
df['revenue'] = df['price'] * df['quantity']
display(df[['price', 'quantity', 'revenue']].head())Exit:
# 2. Apply of functions in conditional logic
When your transformation requires logic that cannot be expressed in basic arithmetic, .apply() allows you to pass a function by column or row.
What we want to do: Assign a shipping priority label based on days until shipping.
def shipping_label(days):
if days Exit:
Using .apply() it’s tidy, readable, and much easier to debug than a loop. Apply it when your logic is conditional and np.where() Or np.select() feels too nested.
# 3. Apply np.where() for binary conditions
When you have a binary condition – one result if true, the other if false – np.where() it’s a tidy and quick choice.
What we want to do: Mark orders where the customer qualifies for a senior discount.
df['senior_discount'] = np.where(df['customer_age'] >= 60, True, False)
display(df[['customer_age', 'senior_discount']].head())Exit:
np.where() it is fully vectorized and much faster than .apply() for basic conditions true or false. Think of it as a vector ternary operator.
# 4. Selecting multiple conditions with np.select()
If you have more than two conditions, np.select() allows you to define a list of conditions and their corresponding values without the need to nest if/elif strings.
What we want to do: Assign a regional tax rate.
conditions = [
df['region'] == 'North',
df['region'] == 'South',
df['region'] == 'East',
df['region'] == 'West',
]
tax_rates = [0.08, 0.06, 0.07, 0.09]
df['tax_rate'] = np.select(conditions, tax_rates, default=0.07)
df['tax_amount'] = df['price'] * df['tax_rate']
display(df[['region', 'price', 'tax_rate', 'tax_amount']].head())Exit:
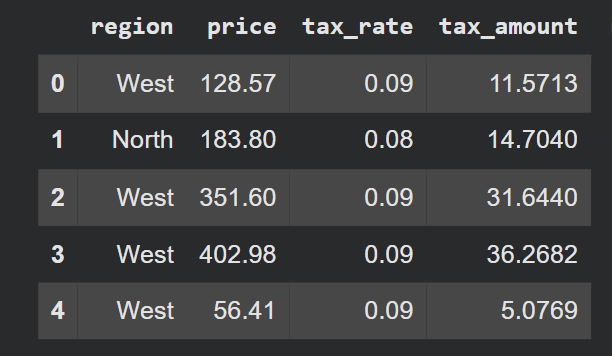
np.select() evaluates all conditions in order and selects the first match. The default The parameter handles anything that doesn’t match, which is useful as a safeguard.
# 5. Value mapping using dictionary search
When you need to translate values in a column – for example, mapping category names to numeric codes or replacing keys with labels – .map() with the dictionary is tidy and quick.
What we want to do: Map product categories to internal department codes.
category_codes = {
'Electronics': 'ELEC',
'Clothing': 'CLTH',
'Home & Kitchen': 'HOME',
'Sports': 'SPRT',
'Books': 'BOOK',
}
df['dept_code'] = df['product_category'].map(category_codes)
display(df[['product_category', 'dept_code']].head())Exit:
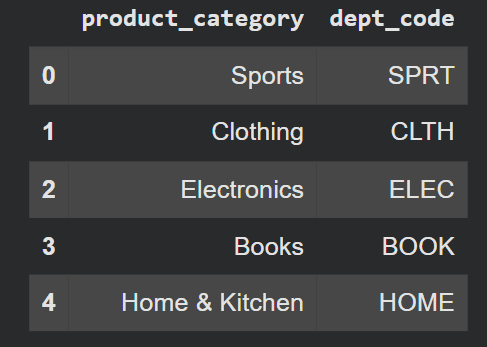
.map() acts as a lookup table. This is one of the least used tools in pandas – we often employ it .apply(lambda x: dict[x]) When .map(dict) does the same thing faster.
# 6. Manipulating strings with .str Accessor
String manipulation is where people most often default to or loops .apply(). The .str accessor allows you to perform string operations on an entire column without any of them.
What we want to do: extract first word from product_category column and convert it to lowercase.
df['category_slug'] = df['product_category'].str.split().str[0].str.lower()
display(df[['product_category', 'category_slug']].head())Exit:
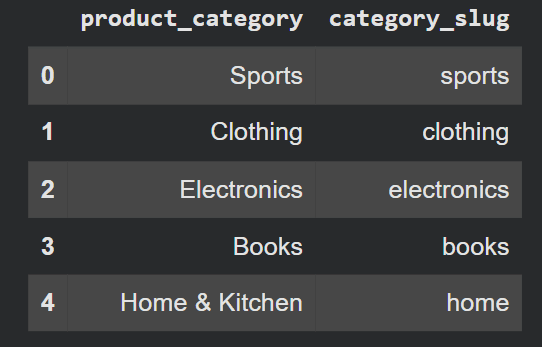
Can be chained .str methods the same as regular Python string methods. Also supportive .str.contains(), .str.replace(), .str.extract() for and more.
# 7. Aggregate groups using .groupby()
A common loop pattern is to iterate over subsets of the data to compute group-level statistics. .groupby() supports this natively.
What we want to do: Calculate total revenue and average shipping days by product category.
summary = (
df.groupby('product_category')
.agg(
total_revenue=('revenue', 'sum'),
avg_ship_days=('days_to_ship', 'mean'),
order_count=('order_id', 'count')
)
.round(2)
.reset_index()
)
summaryExit:
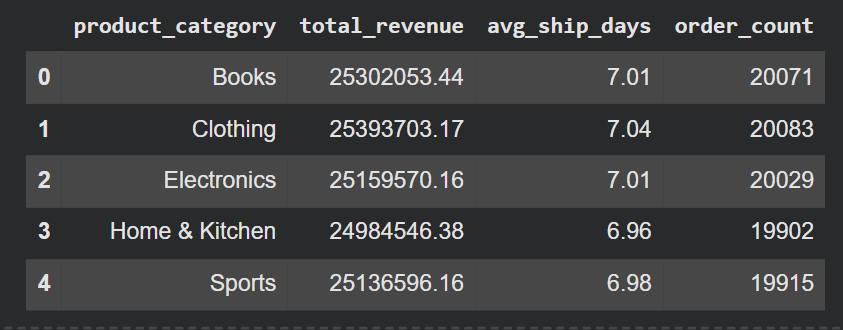
# Choosing the right tool
Most transformations for which you can write a loop fit perfectly into one of these patterns:
| Action/method | Apply case/description |
|---|---|
| Column arithmetic |
Perform vectorized math operations such as addition, subtraction, multiplication, and division directly on DataFrame columns. |
Vectorized operations (*, +e.t.c.) |
Efficiently apply element operations across entire columns without explicit loops. |
| A basic true/false condition |
Evaluate logical conditions to filter or create conditional columns. |
np.where() |
Apply conditional (if-else) logic in a vector manner to DataFrame arrays and columns. |
| Many conditions, many results |
Handle sophisticated conditional logic with multiple rules and results. |
np.select() |
Select values based on multiple conditions and return appropriate output. |
| Value substitution via search |
Swap values using mapping dictionaries for quick transformations. |
.map(dict) |
Map values in a series using a dictionary or substitution function. |
.apply() |
Apply custom functions to rows or columns for versatile transformations. |
| String manipulation |
Apply vectorized string operations with method |
.groupby() + .agg() |
Group data and calculate aggregate statistics such as sum, average, count, etc. |
Once you start thinking in terms of columns rather than rows, you’ll find that the pandas API starts to feel less like a workaround and more like the actual intended way of working.
Bala Priya C is a software developer and technical writer from India. He likes working at the intersection of mathematics, programming, data analytics and content creation. Her areas of interest and specialization include DevOps, data analytics and natural language processing. She enjoys reading, writing, coding and coffee! He is currently working on learning and sharing his knowledge with the developer community by writing tutorials, guides, reviews, and more. Bala also creates engaging resource overviews and coding tutorials.