

{kind=link}

Photo by the author
Strong Python and SQL skills are vital for many data professionals. As a data scientist, you’re probably familiar with Python programming – so much so that writing Python code feels quite natural. But are you following best practices when working on data science projects in Python?
While it’s straightforward to learn Python and build data science applications with it, it may be easier to write code that is complex to maintain. To assist you write better code, this tutorial covers some Python coding best practices that assist with dependency management and maintainability, such as:
- Configuring dedicated virtual environments when working on data analysis projects locally
- Improve maintainability with type guidance
- Data modeling and validation using Pydantic
- Profiling code
- Use vector operations whenever possible
So let’s get coding!
1. Use virtual environments in every project
Virtual environments provide isolation of project dependencies, preventing conflicts between different projects. In data science, where projects often involve different sets of libraries and versions, virtual environments are particularly useful for maintaining reproducibility and effectively managing dependencies.
Additionally, virtual environments make it easier for collaborators to set up the same development environment without worrying about conflicting dependencies.
You can utilize tools like Poetry to create and manage virtual environments. There are many benefits to using Poetry, but if you just need to create virtual environments for your projects, you can also utilize built-in Venv module.
If you are using a Linux (or Mac) computer, you can create and activate virtual environments as follows:
# Create a virtual environment for the project
python -m venv my_project_env
# Activate the virtual environment
source my_project_env/bin/activate
If you are a Windows user, you can check documents how to activate the virtual environment. Therefore, using virtual environments in any project is helpful in keeping dependencies isolated and consistent.
2. Add type tips for maintainability
Because Python is a dynamically typed language, you do not need to specify the data type of the variables you create. However, you can add type hints – indicating the expected type of data – to make your code easier to maintain.
Let’s take an example of a function that calculates the average of a numerical feature in a dataset with appropriate annotations like:
from typing import List
def calculate_mean(feature: List[float]) -> float:
# Calculate mean of the feature
mean_value = sum(feature) / len(feature)
return mean_value
In this case, the type hints tell the user that calcuate_mean function takes a list of floating point numbers and returns a floating point value.
Note that Python does not enforce types at runtime. But you can utilize mypy or similar to report errors for invalid types.
3. Model your data with Pydantic
Earlier we talked about adding type hints to make your code more maintainable. This works well for Python functions. However, when working with data from external sources, it is often helpful to model the data by defining classes and fields with the expected data type.
You can utilize Python’s built-in data classes, but you don’t have standard support for data validation. With Pydantic you can model your data and also utilize built-in data validation features. To utilize Pydantic, you can install it along with the email validator using pip:
$ pip install pydantic[email-validator]Here is an example of modeling customer data with Pydantic. You can create a model class from which it inherits BaseModel and define various fields and attributes:
from pydantic import BaseModel, EmailStr
class Customer(BaseModel):
customer_id: int
name: str
email: EmailStr
phone: str
address: str
# Sample data
customer_data = {
'customer_id': 1,
'name': 'John Doe',
'email': 'john.doe@example.com',
'phone': '123-456-7890',
'address': '123 Main St, City, Country'
}
# Create a customer object
customer = Customer(**customer_data)
print(customer)
You can go further by adding validation to check that all fields have valid values. If you need a tutorial on using Pydantic – defining models and validating data – read Pydantic Tutorial: Simplify Data Validation in Python.
4. Profile code identifying performance bottlenecks
Profiling code is helpful if you want to optimize your application for performance. In data science projects, you can profile memory usage and execution times depending on context.
Let’s say you’re working on a machine learning project where preprocessing a gigantic data set is a key step before training the model. Let’s profile a function that applies common preprocessing steps such as standardization:
import numpy as np
import cProfile
def preprocess_data(data):
# Perform preprocessing steps: scaling and normalization
scaled_data = (data - np.mean(data)) / np.std(data)
return scaled_data
# Generate sample data
data = np.random.rand(100)
# Profile preprocessing function
cProfile.run('preprocess_data(data)')
After running the script, you should see a similar result:
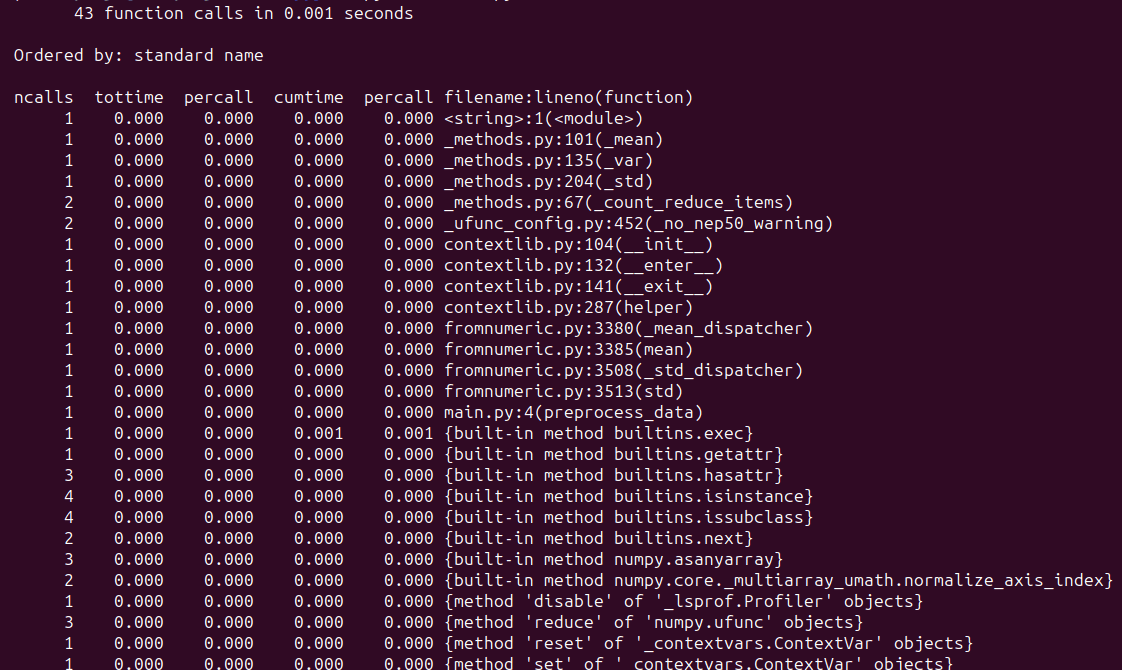
In this example we are profiling preprocess_data() a function that preprocesses sample data. Overall, profiling helps identify potential bottlenecks and aids in optimization to improve performance. Here are some Python profiling tutorials you might find helpful:
5. Use NumPy’s vector operations
For any data processing task, you can always write a Python implementation from scratch. But you may not want to do this when working with gigantic arrays of numbers. For most common operations that can be formulated as vector operations that need to be performed, you can utilize NumPy to perform them more efficiently.
Let’s take the following example of elementary multiplication:
import numpy as np
import timeit
# Set seed for reproducibility
np.random.seed(42)
# Array with 1 million random integers
array1 = np.random.randint(1, 10, size=1000000)
array2 = np.random.randint(1, 10, size=1000000)
Here are the implementations for Python and NumPy only:
# NumPy vectorized implementation for element-wise multiplication
def elementwise_multiply_numpy(array1, array2):
return array1 * array2
# Sample operation using Python to perform element-wise multiplication
def elementwise_multiply_python(array1, array2):
result = []
for x, y in zip(array1, array2):
result.append(x * y)
return result
Let’s take advantage of timeit function z timeit module for measuring the implementation times of the above implementations:
# Measure execution time for NumPy implementation
numpy_execution_time = timeit.timeit(lambda: elementwise_multiply_numpy(array1, array2), number=10) / 10
numpy_execution_time = round(numpy_execution_time, 6)
# Measure execution time for Python implementation
python_execution_time = timeit.timeit(lambda: elementwise_multiply_python(array1, array2), number=10) / 10
python_execution_time = round(python_execution_time, 6)
# Compare execution times
print("NumPy Execution Time:", numpy_execution_time, "seconds")
print("Python Execution Time:", python_execution_time, "seconds")
We can see that the NumPy implementation is ~100 times faster:
Output >>>
NumPy Execution Time: 0.00251 seconds
Python Execution Time: 0.216055 seconds
Summary
In this tutorial, we’ve covered some Python coding best practices for data science. I hope you found them helpful.
If you are interested in learning Python for data science, check out 5 free Master Python for Data Science courses. Have a nice studying!
Bala Priya C is a software developer and technical writer from India. He likes working at the intersection of mathematics, programming, data analytics and content creation. Her areas of interest and specialization include DevOps, data analytics and natural language processing. She enjoys reading, writing, coding and coffee! He is currently working on learning and sharing his knowledge with the developer community by writing tutorials, guides, reviews, and more. Bala also creates captivating resource overviews and coding tutorials.