
")
{kind=link}
# Entry
I know that when beginners start learning machine learning, everything seems uncomplicated at first. You follow a tutorial that asks you to load a dataset, train a model, and then you see something like this: loss = "mse" Or criterion = nn.CrossEntropyLoss().
# What is a loss function?
The loss function is how a machine learning model knows how wrong it is. That’s literally the whole concept. The model makes a prediction. The loss function compares this prediction with the correct answer. He then gives the model a number that says, “Here’s how bad your mistake was.”
AND high loss means the model was very bad.
AND low loss means the model was close.
During training, the model adapts so that the loss is smaller.
This is how learning happens. If you have played a game of darts, the situation is very similar. You throw a dart. To improve, you need feedback. You need to know whether your arrow was slightly off, far, too high, or too far to the left. Without this feedback you cannot improve. So the bullseye is basically the correct answer and the arrow is the prediction. You measure the distance between the dart and the target. The loss function measures how far the dart landed. This distance becomes the model’s feedback signal. Here’s what it would look like if you prefer a visual.
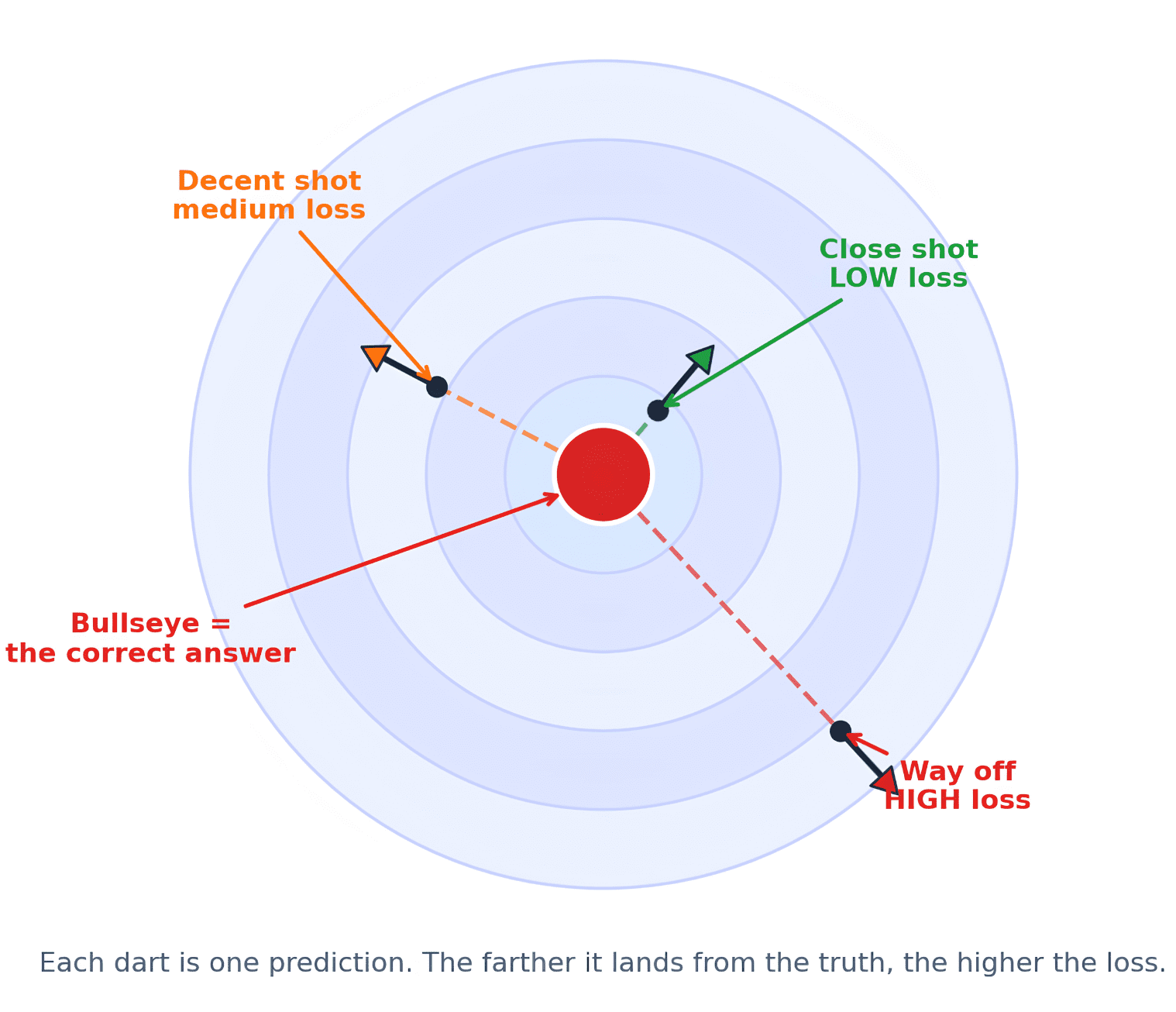
Just as distance from center matters, throwing too close is not the same as too far away. Similarly, in the case of models, simply knowing that the answer is wrong is not enough. To improve, the model must know how badly it has failed.
Now that we understand what a loss function is and why we need one, let’s look at some of them typical loss functions used in machine learning.
# Mean square error
The most common loss in predicting numbers is the mean square error (MSE). It is often used when the model predicts numbers such as house prices, temperatures, or delivery times. The idea is very uncomplicated.
- Mistake: For each prediction, calculate the difference between your guess and the truth.
- Square: Multiply each gap by itself.
- Have in mind: Average all gap squares.
You can write it in Python like this:
def mean_squared_error(predictions, actuals):
squared_errors = [(p - a) ** 2 for p, a in zip(predictions, actuals)]
return sum(squared_errors) / len(squared_errors)I know that taking the errors and then averaging the forecasts makes intuitive sense, but understanding why we equalize them can be confusing. This happens for two reasons:
- Squaring makes any error positive. A +3 error and a -3 error are equally bad, and squaring both gives 9, so they stop canceling each other out.
- Squaring penalizes vast errors much more severely than tiny ones. This is good for many operate cases. For example, if you are predicting house prices, an error of $1,000 versus $200,000 should be penalized accordingly.
# Mean absolute error
Another popular loss function is the mean absolute error (MAE). MAE also measures the difference between predictions and actual values, but does not square the error. Instead, it simply takes an absolute value.
Here is a Python function that will write this:
def mean_absolute_error(predictions, actuals):
absolute_errors = [abs(p - a) for p, a in zip(predictions, actuals)]
return sum(absolute_errors) / len(absolute_errors)So it punishes substantial mistakes, but not as severely as MSE.
- A 10 mistake costs 10 and a 20 mistake costs 20.
- If your data naturally has some outliers and you don’t want your model to overreact, MAE will be a good choice.
I’ll show you a quick chart comparing the MSE and MAE curves.

# Loss between entropy
So far we have talked about predicting numbers. However, many of the problems in machine learning involve category prediction.
Is this email spam or not?
Is this a photo of a cat, dog or fish?
Is a transaction fraudulent or not?
For classification tasks, models typically generate probabilities such as:
Dog: 70%
Cat: 20%
Fish: 10%If the image really shows a dog, this is a good prediction. However, if it is a cat, then the model should be penalized for assigning a lower probability to the correct answer.
So the intuition is:
- Correct and reliable – low loss
- Correct, but not sure – average loss
- Livid and self-confident – a great loss
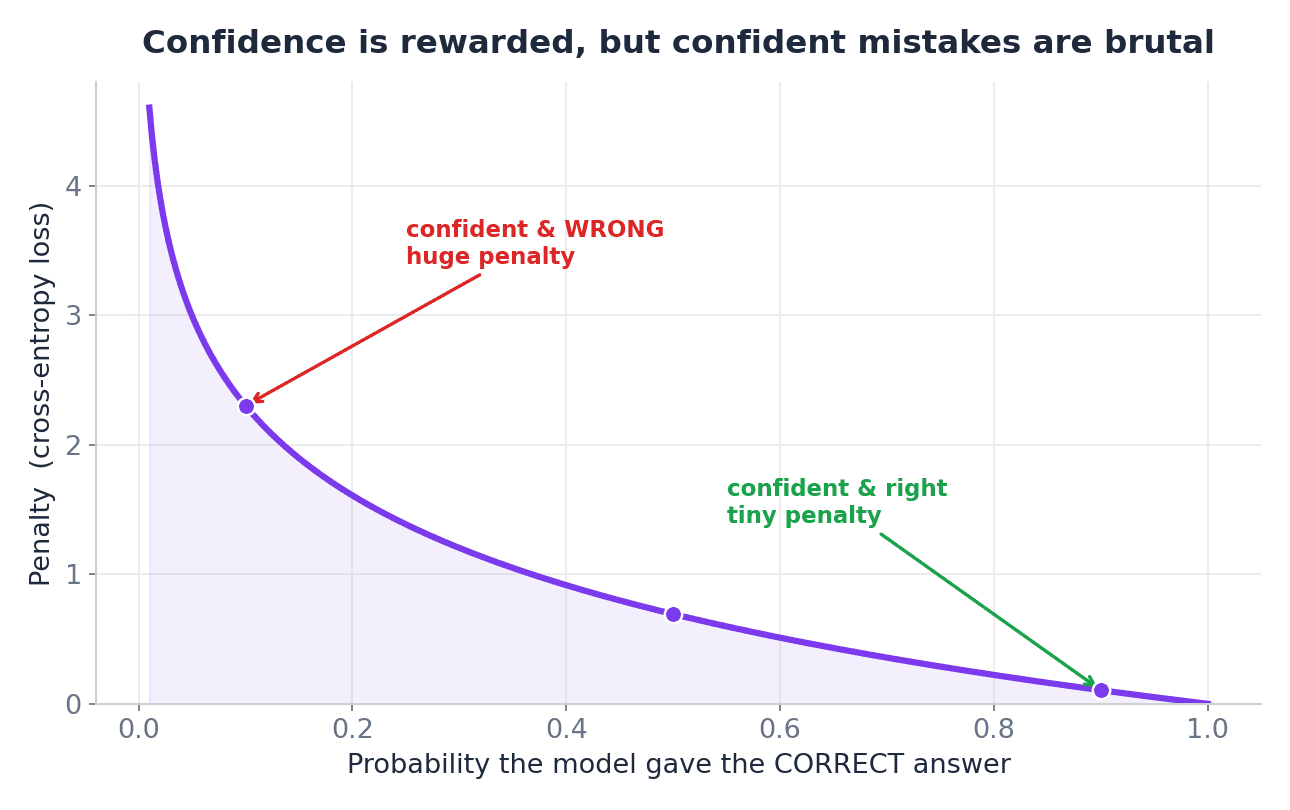
This is why cross-entropy is so widely used for classification. It’s not just about whether the model was right. What also matters is how confident the model was.
# Loss and accuracy
Now that we have gone through the different loss functions, I also want to explain the difference between loss and precision. It’s not the same.
Accuracy he tells you how many predictions came true.
But loss he tells you how solemn the model’s mistakes were.
If you have two models – Model A and Model B – and in both cases 90 out of 100 predictions are correct, they will have the same accuracy. But one model may be very confident in the right answers and only slightly wrong in the wrong ones, while the other may be barely correct in many examples and extremely confident when wrong.
In this case, the accuracy would be the same, but the loss would be different.
# Training Loop
Once the model has a loss count, it can be improved. The training loop looks like this:
- The model makes predictions.
- The loss function measures errors.
- The optimizer updates the model.
- The model tries again.
- Let’s hope that the losses will be smaller.
When training the model, we also plot the loss over time. At the beginning, the model makes many mistakes and makes penniless predictions, so the loss is vast. However, as learning progresses, the loss decreases and the model becomes better at predicting.
A hearty training curve often looks like this:
High loss at the beginning → keen decline → gradual flattening
as seen in the figure below.

Flattening is normal. This means that the model has learned uncomplicated patterns and is now making smaller improvements. However, if training losses are decreasing and validation losses are starting to escalate, this may be a warning sign overfitting — which means the model can remember training data, rather than learning patterns that generalize.
# Final thoughts
The loss function is the result of the model error.
It tells the model how wrong its predictions are and gives the training a clear goal: to reduce that number.
Once you understand loss functions, many other machine learning ideas become easier to understand – including gradient descent, backpropagation, optimization, overfitting, and evaluation metrics.
You don’t have to start with scary equations. Start with an idea:
- The model guesses.
- The loss function evaluates guessing.
- The model updates itself to reduce the score.
This is the essence of machine learning.
The loss is that the model knows it is wrong.
Training teaches you how to make less mistakes.
Kanwal Mehreen is a machine learning engineer and technical writer with a deep passion for data science and the intersection of artificial intelligence and medicine. She is co-author of the e-book “Maximizing Productivity with ChatGPT”. As a 2022 Google Generation Scholar for APAC, she promotes diversity and academic excellence. She is also recognized as a Teradata Diversity in Tech Scholar, a Mitacs Globalink Research Scholar, and a Harvard WeCode Scholar. Kanwal is a staunch advocate for change and founded FEMCodes to empower women in STEM fields.