

{kind=link}
Photo by the author
# Entry
Search Assisted Generation (RAG) systems are, simply put, the natural evolution of stand-alone Gigantic Language Models (LLM). RAG addresses several key limitations of classic LLMs such as model hallucinations or a lack of current, relevant knowledge needed to generate reasonable, fact-based responses to user inquiries.
These seven steps are associated with different stages or components of the RAG environment, as shown in the numeric labels ([1] Down [7]) in the diagram below, which illustrates the classic RAG architecture:
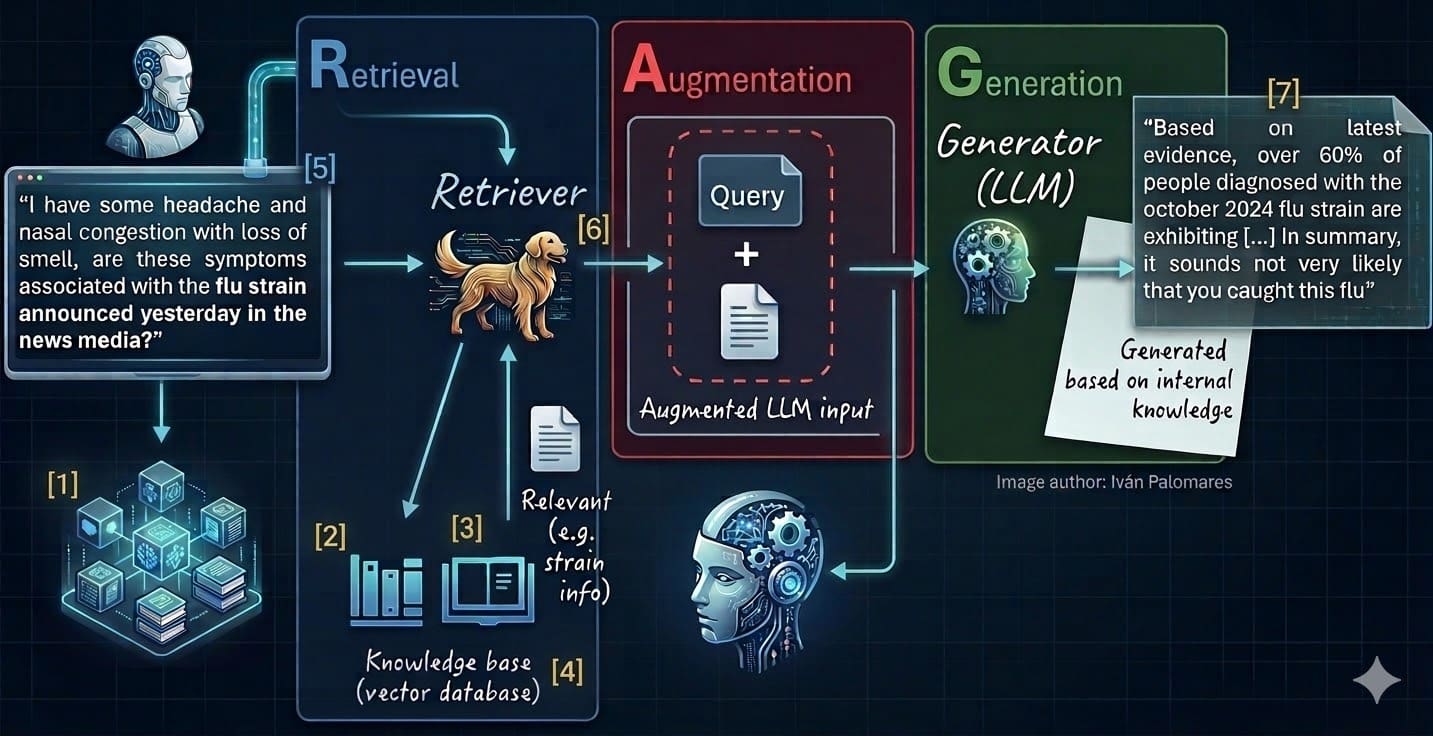
7 steps to mastering RAG systems (see labels 1-7 and list below)
- Select and clear data sources
- Dividing and dividing
- Embedding/vectorization
- Filling vector databases
- Query vectorization
- Get the right context
- Generate a reasoned response
# 1. Selecting and cleaning data sources
The principle of “garbage in, garbage out” takes on maximum importance at RAG. Its value is directly proportional to the relevance, quality and purity of the source text data it can retrieve. To ensure high-quality knowledge bases, identify high-value data silos and periodically audit your databases. Before ingesting raw data, perform an effective cleansing process with strong pipelines that include critical steps such as removing personally identifiable information (PII), eliminating duplicates, and dealing with other confounding elements. This is an ongoing engineering process that must be applied every time modern data is incorporated.
You can read this article to learn data cleansing techniques.
# 2. Splitting and dividing documents
Many instances of text data or documents, such as literary novels or doctoral theses, are too enormous to be embedded as a single instance or unit of data. Chunking involves dividing long texts into smaller parts that maintain semantic meaning and contextual integrity. It requires a careful approach: not too many fragments (resulting in a possible loss of context), but also not too few – too enormous fragments later affect the semantic search!
There are different approaches to chunking, from those based on the number of characters to those based on logical boundaries such as paragraphs or sections. Llama Index AND LangChainalong with related Python libraries, can certainly support with this task by implementing more advanced splitting mechanisms.
Chunking can also take into account overlaps between parts of a document to maintain consistency in the search process. To illustrate, this is what the chunking might look like on a miniature, toy-sized text:
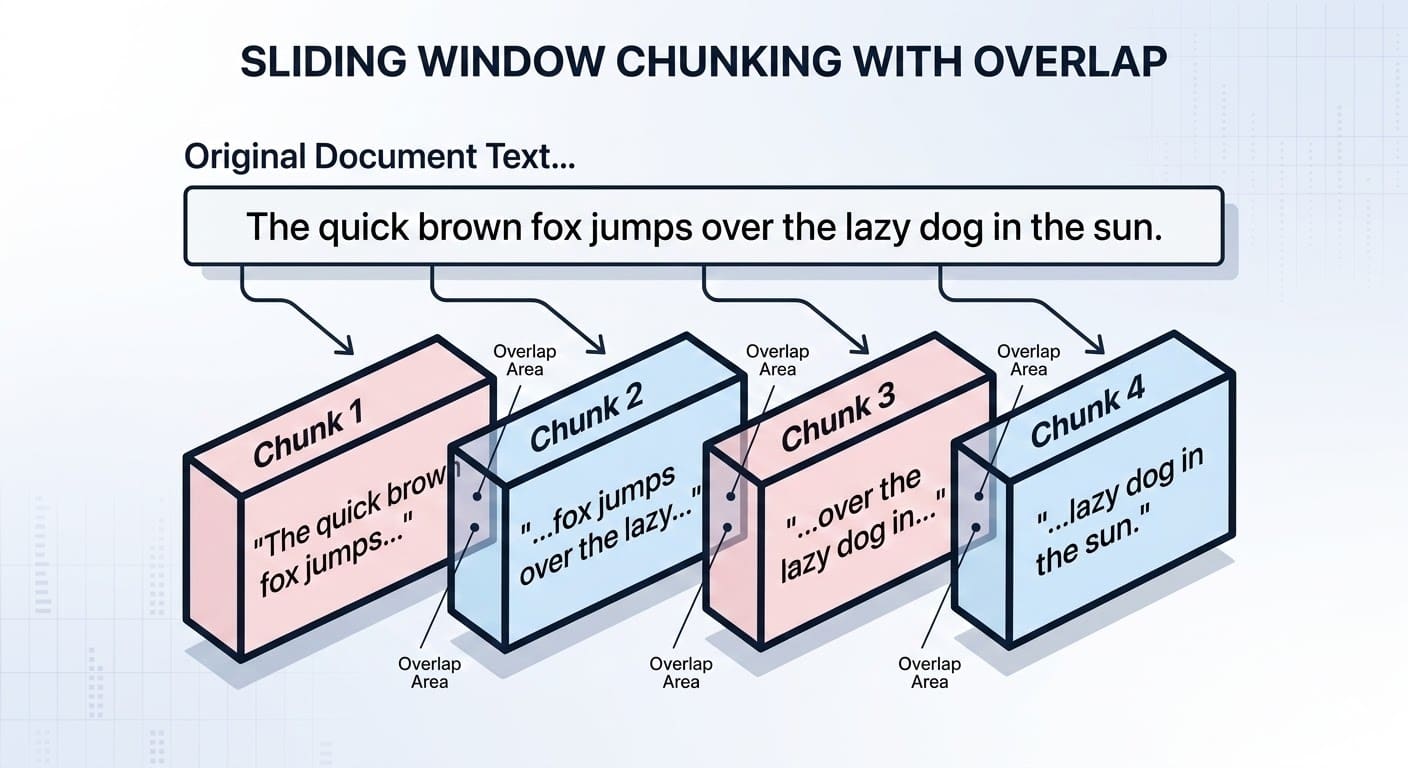
Dividing documents in RAG systems with tabs | Photo by the author
# 3. Document embedding and vectorization
The next step, before documents are broken into pieces, before they are stored safely in a knowledge base, is to translate them into “machine language”: numbers. This is typically done by converting each text into a vector embedding – a dense, multi-dimensional numerical representation that captures the semantic characteristics of the text. In recent years, specialized LLMs have been created to perform this task: they are called embedding models and include well-known open source options such as Hugging faces all-MiniLM-L6-v2.
Learn more about embeddings and their advantages over classic text representation approaches in this article.
# 4. Filling the vector database
Unlike conventional relational databases, vector databases are designed to effectively enable the search process through multidimensional arrays (embeddings) that represent text documents – a critical step for RAG systems in retrieving relevant documents based on a user’s query. Both open source vector stores like FAISS or freemium alternatives such as Cone exist and can provide excellent solutions, thus bridging the gap between human-readable text and math-like vector representations.
This snippet is used to split text (see point 2 earlier) and populate a local, free vector database using LangChain and Chroma – assuming we have a long document to store in a file called knowledge_base.txt: :
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
# Load and chunk the data
docs = TextLoader("knowledge_base.txt").load()
chunks = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50).split_documents(docs)
# Create text embeddings using a free open-source model and store in ChromaDB
embedding_model = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
vector_db = Chroma.from_documents(documents=chunks, embedding=embedding_model, persist_directory="./db")
print(f"Successfully stored {len(chunks)} embedded chunks.")Read more about vector databases Here.
# 5. Query vectorization
User suggestions expressed in natural language are not directly matched to stored document vectors: they too must be translated using the same embedding mechanism or model (see step 3). In other words, a single query vector is created and compared with the vectors stored in the knowledge base to retrieve, based on similarity metrics, the most relevant or similar documents.
# 6. Retrieving the appropriate context
Once the query is vectorized, the RAG retrieval module performs a similarity-based search to find the closest matching vectors (document fragments). While conventional top-k approaches often work well, advanced methods such as fusion retrieval and reranking can be used to optimize how the obtained results are processed and integrated into the final enriched LLM prompt.
Check out this related article for more information about these advanced mechanisms. Similarly, managing context windows is another crucial process to employ when the LLM’s ability to handle very enormous volumes is constrained.
# 7. Generating reasoned responses
Finally, the LLM comes into the picture, accepts the extended user’s query with the retrieved context, and is instructed to answer the user’s question using that context. In a properly designed RAG architecture, following the previous six steps will usually lead to more true, defensible answers that may even include citations to our own data used to build the knowledge base.
At this stage, assessing the quality of the response is imperative to measure the behavior of the entire RAG system and to signal when the model may require tuning. Evaluation framework were established for this purpose.
# Application
RAG systems or architectures have become an almost indispensable aspect of LLM-based applications, and commercial, large-scale applications now rarely omit them. RAG makes LLM applications more strong and knowledge-intensive, and helps these models generate reasoned, evidence-based answers, sometimes based on privately owned data in organizations.
The article summarizes seven key steps to mastering the process of constructing RAG systems. Once you have this foundational knowledge and skills, you’ll be able to develop enhanced LLM applications that unlock enterprise-grade performance, accuracy, and transparency – something that’s not possible with the well-known models used on the Internet.
Ivan Palomares Carrascosa is a thought leader, writer, speaker and advisor in the fields of Artificial Intelligence, Machine Learning, Deep Learning and LLM. Trains and advises others on the operate of artificial intelligence in the real world.