

{kind=link}
Photo by the editor
# Entry
Rise large language models (LLM) such as GPT-4, LamaAND Claudius changed the world of artificial intelligence. These models can write code, answer questions, and summarize documents with incredible competence. For data scientists, this modern era is truly exhilarating, but it also presents a unique challenge in that the performance of these powerful models is fundamentally tied to the quality of the data on which they are based.
While much of the public discussion focuses on the models themselves, artificial neural networks and the mathematics of attention, the overlooked hero of the LLM era is data engineering. Ancient data management policies are not being replaced; are modernized.
In this article, we’ll look at how the role of data is changing, the critical pipelines required to support both training and inference, and modern architectures like RAGthat define how applications are created. If you’re an aspiring data scientist and want to understand how your work fits into this modern paradigm, this article is for you.
# Moving from BI data to AI-ready data
Traditionally, the main focus has been on data engineering business intelligence (BI). The goal was to move data from operational databases, such as transaction records, into a data warehouse. This data was very structured, neat, and organized into rows and columns to answer questions such as: “What were sales like in the last quarter?“
Age LLM requires a deeper look. Now we need to support each other artificial intelligence (AI). This involves handling unstructured data such as text in PDF files, customer call transcripts, and code in a GitHub repository. The goal is no longer just to collate this data, but to transform it so that the model can understand and reason about it.
This change requires a modern type of data pipeline that handles different types of data and prepares it for three different stages of the LLM lifecycle:
- Initial training and fine-tuning: Teaching a model or specializing it for a task.
- Inference and reasoning: Helping the model access modern information when asked a question.
- Assessment and Observability: Ensuring that the model performs accurately, safely and without bias.
Let’s discuss the data engineering challenges in each of these phases.
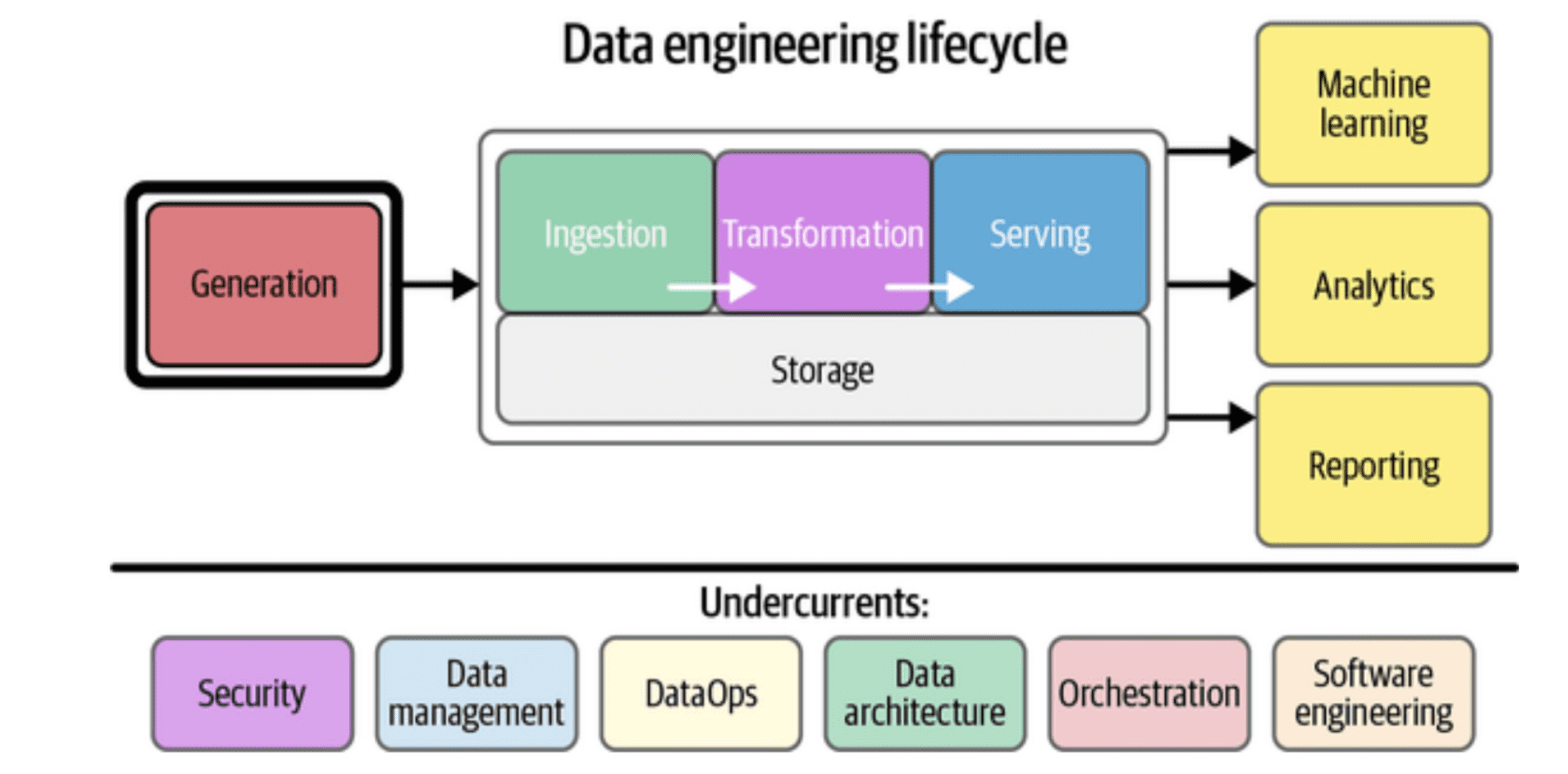
Figure 1: Data engineering lifecycle
# Phase 1: Engineering data for LLM training
Before a model can be helpful, it must be trained. This phase is data engineering on a massive scale. The goal is to collect a high-quality text dataset that represents a significant portion of the world’s knowledge. Let’s look at the pillars of training data.
// Understanding the three pillars of training data
When building a dataset for LLM pre-training or tuning, data engineers need to focus on three vital aspects:
- LLMs learn by recognizing statistical patterns. To understand minute differences, grammar and reasoning, they need to be exposed to trillions of tokens (pieces of words). This means consuming petabytes of data from sources such as Crawling together, GitHubscientific articles and online archives. A huge amount requires distributed processing frameworks such as Apache Spark to handle the data load.
- A model trained solely on legal documents will be terrible at writing poetry. Another data set is vital for generalization. Data engineers must build pipelines that pull data from thousands of different domains to create a balanced dataset.
- Quality is the most vital factor to consider. This is where the real work begins. The Internet is full of noise, spam, boilerplate text (such as navigation menus), and false information. Celebrated article from Databricks: “The secret to speeding up your LLM training 1000 times“, emphasized that data quality is usually more vital than model architecture.
- Pipelines must remove low-quality content. This includes deduplication (removing nearly identical sentences or paragraphs), filtering text in a non-target language, and removing unsafe or harmful content.
- You need to know where your data comes from. If your model behaves unexpectedly, you should trace its behavior in the source data. This is the practice data lineageand becomes a critical compliance checking and debugging tool
For a data scientist, understanding that a model is only as good as its training data is the first step toward building reliable systems.
# Phase 2: Adoption of the RAG architecture
While training a base model is a huge undertaking, most companies don’t have to build it from scratch. Instead, they take an existing model and combine it with their own private data. This is where Recovery Assisted Generation (RAG) has become the dominant architecture.
RAG solves the fundamental problem of LLMs being frozen at the point of their training. If you ask a model trained in 2022 about a 2023 event, they will fail. RAG allows the model to “search” for information in real time.
A typical LLM data pipeline for RAG looks like this:
- You have internal documents (PDF files, Confluence pages, Slack archives). The data engineer creates a pipeline to ingest these documents.
- LLMs have a circumscribed “context window” (the amount of text they can process at once). You can’t throw a 500-page manual at a model. Therefore, the pipeline must intelligently divide documents into smaller, understandable parts (e.g. several paragraphs each).
- Each fragment passes through a different model (embedding model) that converts the text into a number vector – a long list of numbers that represents the meaning of the text.
- These vectors are then stored in a specialized database designed for speed: the vector database.
When the user asks a question, the process is reversed:
- The user’s query is converted to a vector using the same embedding model.
- The vector database performs a similarity search, finding text fragments that are most semantically similar to the user’s question.
- The relevant passages are forwarded to LLM along with the original question and a message such as “Please answer the question based solely on the following context.”
// Meeting the challenges of data engineering
The success of RAG depends entirely on the quality of the intake pipeline. If the partitioning strategy is wrong, the context will be corrupted. If the embedding model does not fit your data, the download will retrieve irrelevant information. Data engineers are responsible for controlling these parameters and building reliable pipelines that enable RAG applications to function.
# Phase 3: Building a state-of-the-art data stack for LLM
The procedure for building these pipelines is changing. As a data scientist, you will be exposed to a modern “stack” of technologies designed to support vector search and LLM orchestration.
- Vector databases: These form the core of the RAG stack. Unlike established databases that search for exact matches of keywords, vector databases search by relevance.
- Orchestration structures: These tools aid combine prompts, LLM calls, and data retrievals into a coherent application.
- Examples: LangChain AND Llama Index. They provide ready-made vector storage connectors and templates for common RAG patterns.
- Data processing: Good old-fashioned ETL (extract, transform, load) is still imperative. Tools like Spark are used to neat and prepare the huge datasets needed for tuning.
The bottom line is that the state-of-the-art data stack doesn’t replace the ancient one; this is an extension. You still need a data warehouse (like Snowflake or BigQuery) to perform structured analytics, but now you need a vector store alongside it to support AI features.

Dig. 2: Current Data Stack for LLM
# Phase 4: Assessment and observation
The final piece of the puzzle is evaluation. In established machine learning, you can measure model performance using a basic metric such as accuracy (was this image of a cat or a dog?). With generative AI, the assessment is more nuanced. If the model writes a paragraph, is it precise? Is that clear? Is it protected?
Data engineering plays a role here with the LLM observability. We need to track the data flowing through our systems to correct failures.
Consider a RAG application that gives you the wrong answer. Why didn’t it work?
- Was the appropriate document missing from the vector database? (Data processing error)
- Was the document in the database but a search failed to retrieve it? (Download error)
- Was the document retrieved but LLM ignored it and came up with a response? (Generation failure)
To answer these questions, data engineers build pipelines that record the entire interaction. They store the user’s query, the retrieved context, and the final LLM response. By analyzing this data, teams can identify bottlenecks, filter out bad fetches, and create datasets to tune the model for better performance in the future. This closes the loop, turning the application into a continuous learning system.
# Final remarks
We are entering a phase where artificial intelligence becomes the main interface through which we interact with data. This represents a huge opportunity for data scientists. The skills required to neat, organize and manage data are more valuable than ever.
However, the context has changed. You now need to think about unstructured data with the same caution you once did with structured tables. You need to understand how training data shapes model behavior. You must learn to design LLM data pipelines that support search-assisted generation.
Data engineering is the basis on which reliable, precise and secure AI systems are built. By mastering these concepts, you’re not only keeping up with the trend; you are building infrastructure for the future.
Shittu Olumid is a software engineer and technical writer with a passion for using cutting-edge technology to create compelling narratives, with an eye for detail and a knack for simplifying intricate concepts. You can also find Shittu on Twitter.