

{kind=link}

Photo by the author
# Entry
It seems like almost every week a modern model claims to be state of the art, beating existing AI models in all benchmarks.
I receive free access to the latest AI models during my full-time job within a few weeks of launch. I usually don’t pay much attention to noise and just exploit whichever model is automatically selected by the system.
However, I know developers and friends who want to create AI software that can be sent to production. Because these initiatives are self-financed, the challenge for them is to find the best model to accomplish this task. They want to balance cost and reliability.
So, after the release of GPT-5.2, I decided to conduct a hands-on test to find out if this model was worth the hype and if it was actually better than the competition.
Specifically, I decided to test each vendor’s flagship models: Close job 4.5 (The most powerful model from Anthropic), GPT-5.2 Pro (OpenAI’s latest extended inference model) and DeepSeek V3.2 (one of the newest open source alternatives).
To test these models, I decided to ask them to build a playable Tetris game with a single command.
Here are the metrics I used to evaluate the success of each model:
| Criteria | Description |
|---|---|
| The first attempt was successful | After one question, did the model provide working code? Multiple debugging iterations lead to higher costs over time, which is why this metric was chosen. |
| Completeness of functions | Were all the functions listed in the prompt built by the model, or was something left out? |
| Playability | Apart from the technical implementation, was the game silky? Or were there issues that created friction in the user experience? |
| Profitability | How much did it cost to get production-ready code? |
# Hint
Here is the prompt I entered into each AI model:
Build a fully functional Tetris game as a single HTML file that I can open directly in my browser.
Requirements:
GAME MECHANICS:
– All 7 types of Tetris pieces
– Sleek element rotation with wall reflection collision detection
– Pieces should fall automatically, gradually enhance the speed as the user’s score increases
– Line cleaning with visual animation
– “Next Item” preview window.
– Game over detection when pieces reach the topCONTROLS:
– Arrow keys: Left/Right to move, Down to drop faster, Up to rotate
– Touch controls for mobile devices: swipe left/right to move, swipe down to drop, tap to rotate
– Spacebar to pause/unpause
– Enter key to restart after game completionVISUAL DESIGN:
– Gradient colors for each element type
– Sleek animations when elements move and lines are clear
– Pristine UI with rounded corners
– Update results in real time
– Level indicator
– Game over screen with final score and restart buttonGAMEPLAY AND ENGLISH:
– Sleek gameplay at 60 frames per second
– Particle effects after clearing lines (optional, but impressive)
– Augment score based on the number of lines deleted at once
– Grid background
– Responsive designMake it visually polished and provide a satisfying gaming experience. The code should be immaculate and well-organized.
# Results
// 1. Finish work 4.5
The Opus 4.5 model built exactly what I asked for.
The user interface was immaculate and instructions were clearly displayed on the screen. All controls were responsive and the game was fun to play.
The gameplay was so silky that I actually played for quite some time and moved away from testing other models.
Plus, Opus 4.5 took less than 2 minutes to give me a working game, which impressed me on my first try.
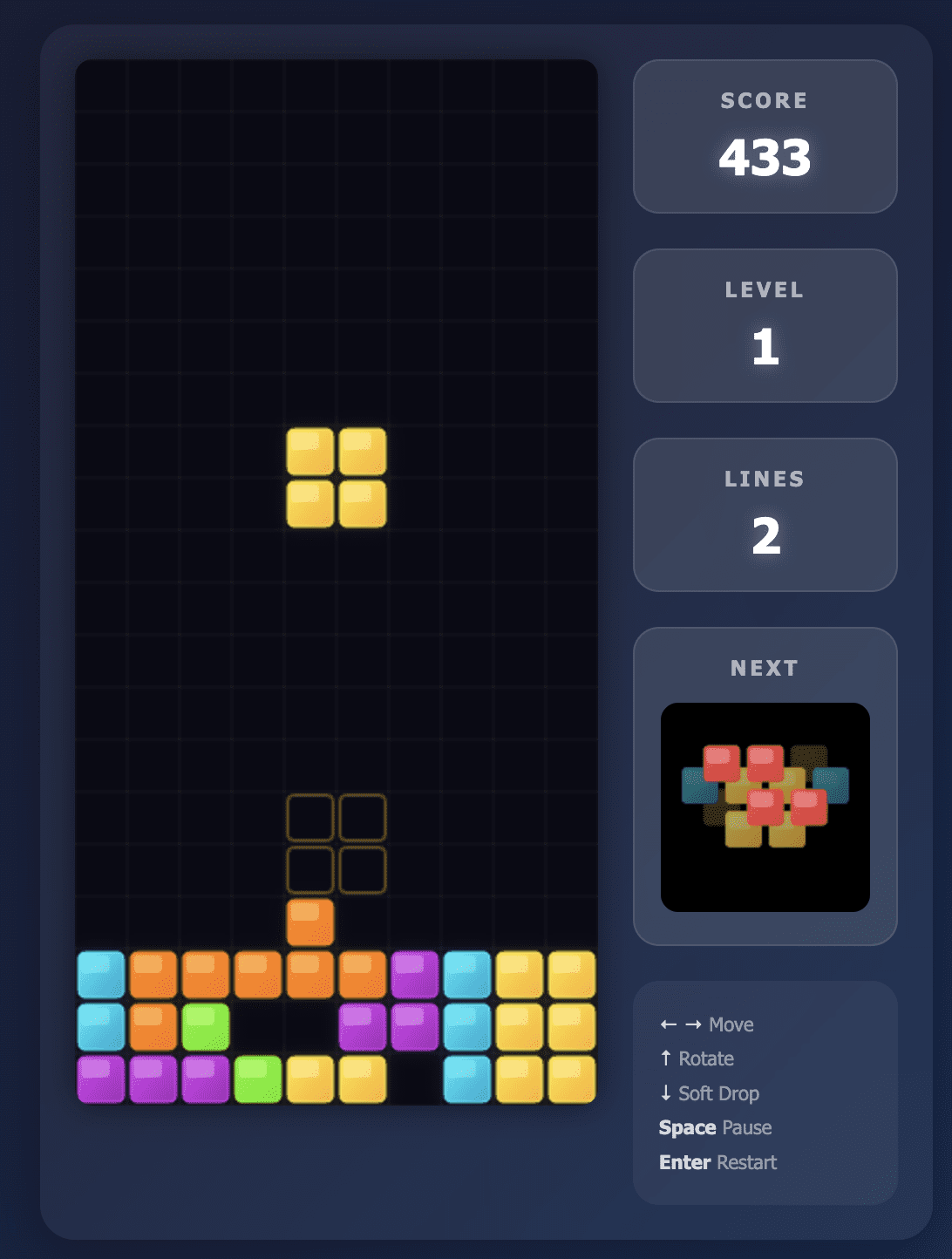
Tetris game built by Opus 4.5
// 2. GPT-5.2 Pro
GPT-5.2 Pro is the latest OpenAI model with extended reasoning. For context, GPT-5.2 has three tiers: Instant, Thinking, and Pro. At the time of writing, GPT-5.2 Pro is their most knowledgeable model, providing enhanced thinking and reasoning capabilities.
It is also 4x more steep than Opus 4.5.
There was a lot of hype around this model, which led me to set high expectations.
Unfortunately, the game this model produced disappointed me.
On the first try, GPT-5.2 Pro created a Tetris game with a layout error. The bottom rows of the game were outside the viewport and I couldn’t see where the pieces landed.
This made the game unplayable as shown in the screenshot below:
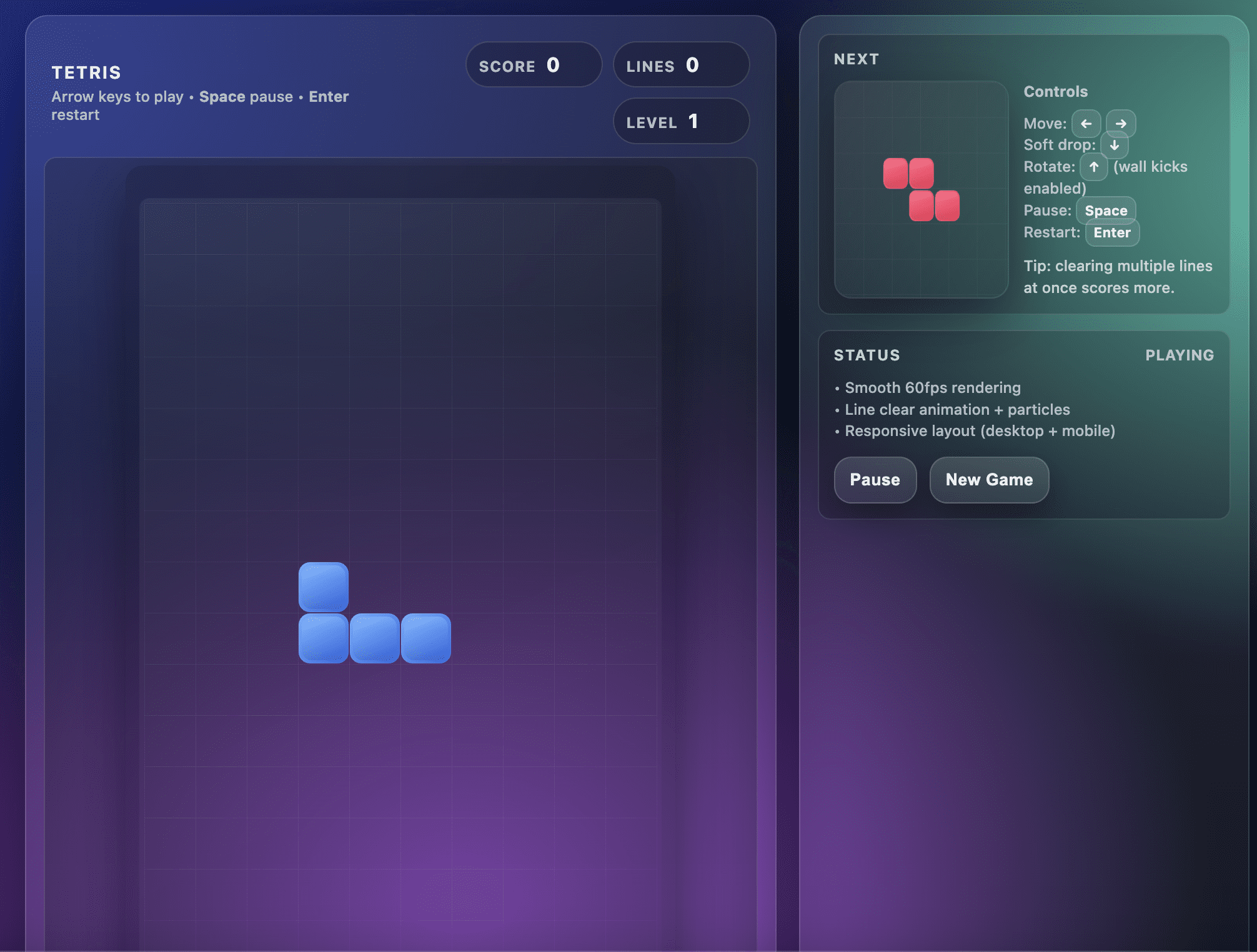
Tetris game built on GPT-5.2
I was particularly surprised by this error because it took the model about 6 minutes to generate this code.
I decided to try again using this prompt to solve the viewport problem:
The game works, but there is a bug. The bottom rows of the Tetris board are cut off at the bottom of the screen. I can’t see the pieces when they land and the canvas extends beyond the noticeable viewport.
Please fix it by:
1. Make sure the entire board fits in the viewport
2. Adding appropriate centering so that the entire board is noticeableThe game should fit on the screen with all lines noticeable.
When prompted, the GPT-5.2 Pro model produced a functional game as seen in the screenshot below:

Second attempt at Tetris by GPT-5.2
However, the gameplay was not as silky as in the Opus 4.5 model.
When I pressed the “down” arrow to make an item fall, the next item would sometimes drop instantly at high speed, not giving me enough time to think about how to position it.
I only found the game playable when I let each piece fall on its own, which wasn’t the best experience.
(Note: I also tried the standard GPT-5.2 model, which produced similar buggy code the first time.)
// 3.DeepSeek V3.2
DeepSeek’s first attempt at creating this game had two problems:
- The pieces began to disappear as they hit the bottom of the screen.
- The “down” arrow, used to drop items faster, scrolled the entire web page rather than just moving the game items.
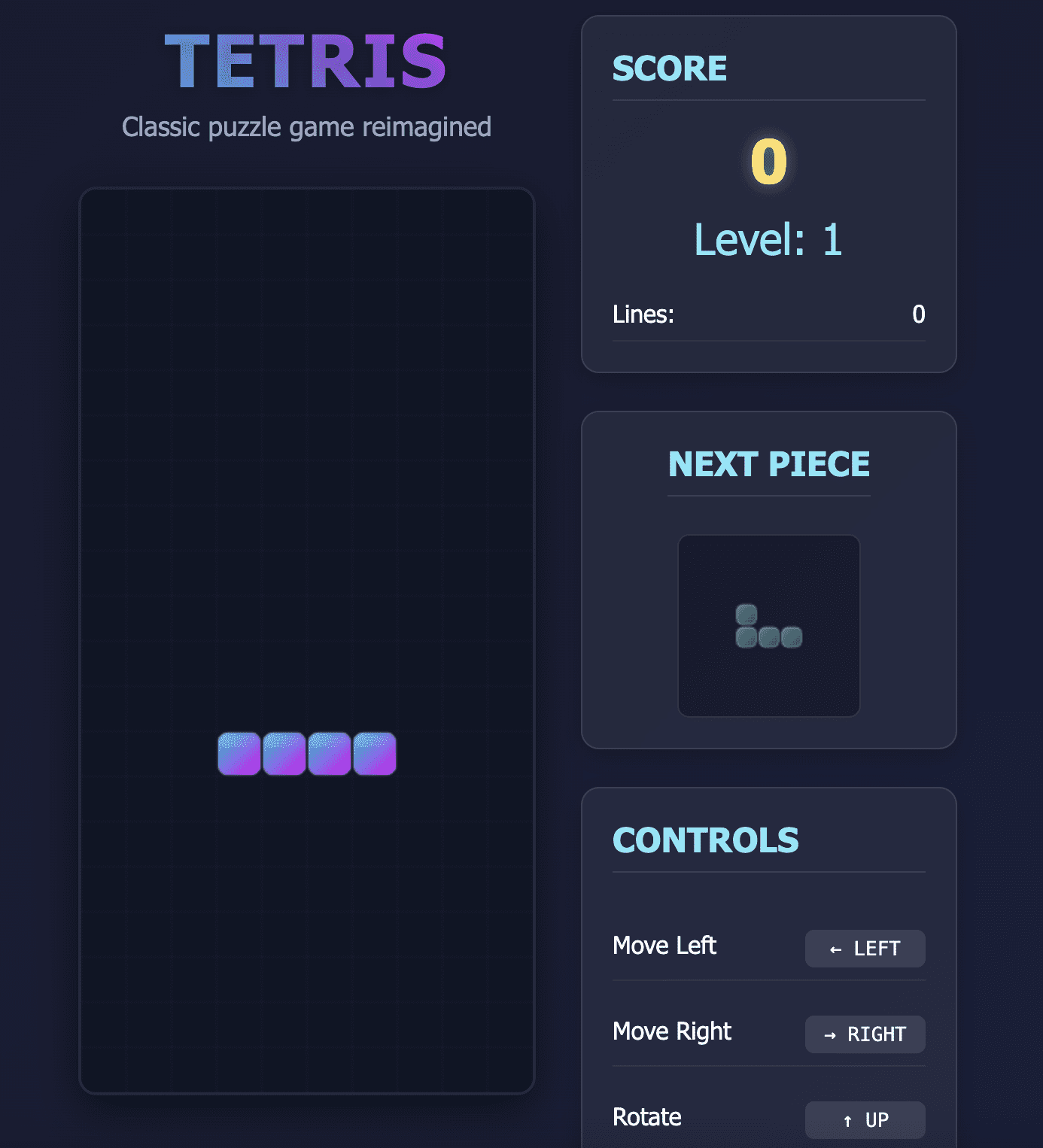
Tetris game built by DeepSeek V3.2
I asked the model again to fix this issue and the gameplay controls worked fine.
However, some pieces still disappeared before they landed. This made the game completely unplayable even after the second iteration.
I’m sure this problem could be solved with 2-3 more prompts, and given DeepSeek’s low price, you could afford 10+ rounds of debugging and still produce less than one successful attempt at Opus 4.5.
# Summary: GPT-5.2 vs Opus 4.5 vs DeepSeek 3.2
// Cost sharing
Here is a price comparison of the three models:
| Model | Input data (per 1 million tokens) | Output (per 1 million tokens) |
|---|---|---|
| DeepSeek V3.2 | $0.27 | $1.10 |
| GPT-5.2 | $1.75 | $14.00 |
| Close job 4.5 | $5.00 | $25.00 |
| GPT-5.2 Pro | $21.00 | $84.00 |
DeepSeek V3.2 is the cheapest alternative, and you can also download the model weights for free and run it on your own infrastructure.
GPT-5.2 is almost 7 times more steep than DeepSeek V3.2, followed by Opus 4.5 and GPT-5.2 Pro.
For this particular task (building the Tetris game) we used approximately 1000 input tokens and 3500 output tokens.
For each additional iteration, we estimate an additional 1,500 tokens per additional round. Here is the total cost incurred for the model:
| Model | Total cost | Result |
|---|---|---|
| DeepSeek V3.2 | ~$0.005 | The game cannot be played |
| GPT-5.2 | ~$0.07 | Playable, but impoverished user experience |
| Close job 4.5 | ~$0.09 | Playable and good service |
| GPT-5.2 Pro | ~$0.41 | Playable, but impoverished user experience |
# To go
Based on my experience creating this game, For everyday coding tasks, I would stick with the Opus 4.5.
Although GPT-5.2 is cheaper than Opus 4.5, I personally wouldn’t exploit it for coding because the iterations required to get the same result would likely result in spending the same amount of money.
However, the DeepSeek V3.2 is much cheaper than the other models on this list.
If you’re a developer on a budget and have time to debug, you’ll still save money even if it takes you more than 10 tries to get the code working.
I was surprised that GPT 5.2 Pro wasn’t able to produce a working game the first time, as it took about 6 minutes to come up with the buggy code. After all, this is OpenAI’s flagship model, and Tetris should be a relatively basic task.
However, GPT-5.2 Pro’s strengths lie in mathematics and science and are specifically designed to solve problems that do not rely on pattern recognition from training data. Perhaps this model is overworked for basic, everyday coding tasks and should instead be used when building something complicated and requiring a novel architecture.
Practical conclusion from this experiment:
- Opus 4.5 is best for everyday coding tasks.
- DeepSeek V3.2 is a budget alternative that provides reasonable performance, although it does require some debugging effort to achieve the desired result.
- GPT-5.2 (Standard) didn’t perform as well as Opus 4.5, while GPT-5.2 (Pro) is probably better suited for complicated reasoning than quick coding tasks like this.
You can repeat this test using the hint I shared above, and ecstatic coding!
Natasha Selvaraj is a self-taught data analyst with a passion for writing. Natasha writes about everything related to data science, she is a true master of all things related to data. You can connect with her LinkedIn or check it out YouTube channel.