

{kind=link}

Image based on Artificial analysis
# Entry
We often talk about petite AI models. But what about petite models that can actually run on a Raspberry Pi with circumscribed CPU power and very little RAM?
Thanks to newfangled architecture and aggressive quantization, models with 1 to 2 billion parameters can now be run on extremely petite devices. Once quantized, these models can be run almost anywhere, even on a shrewd refrigerator. All you need is a llama.cpp file, a quantized model from Hugging Face Hub, and a uncomplicated command to get started.
What makes these miniature models thrilling is that they are not flimsy or obsolete. Many of them outperform much older, huge models at generating real-world text. Some also support tool invocation, vision understanding, and structured results. These are not petite and stupid models. They are petite, brisk and surprisingly bright, capable of running on devices that fit in the palm of your hand.
In this article, we will look at 7 petite AI models that run well on Raspberry Pi and other low-power machines using the llama.cpp file. If you want to experiment with on-premises AI without GPUs, cloud costs, and bulky infrastructure, this list is a great place to start.
# 1. Qwen3 4B 2507
Qwen3-4B-Instrukt-2507 is a compact but highly capable, no-thinking language model that provides a significant performance leap for its size. With just 4 billion parameters, it demonstrates significant benefits in following instructions, logical reasoning, math, science, coding, and tool apply, while also extending long-term knowledge across multiple languages.

The model shows a clearly better match to user preferences in subjective and open-ended tasks, resulting in clearer, more helpful and higher quality generated text. Support for an impressive 256KB native context length enables the capable handling of extremely long documents and conversations, making it a practical choice for real-world applications that require both depth and speed, without the overhead of larger models.
# 2. Qwen3 VL 4B
Qwen3-VL-4B-Instrukt is the most advanced vision language model in the Qwen family to date, combining state-of-the-art multimodal intelligence in a high-performance 4B package. It provides excellent text understanding and generation combined with deeper visual perception, reasoning and spatial awareness, ensuring high performance for images, video and long documents.
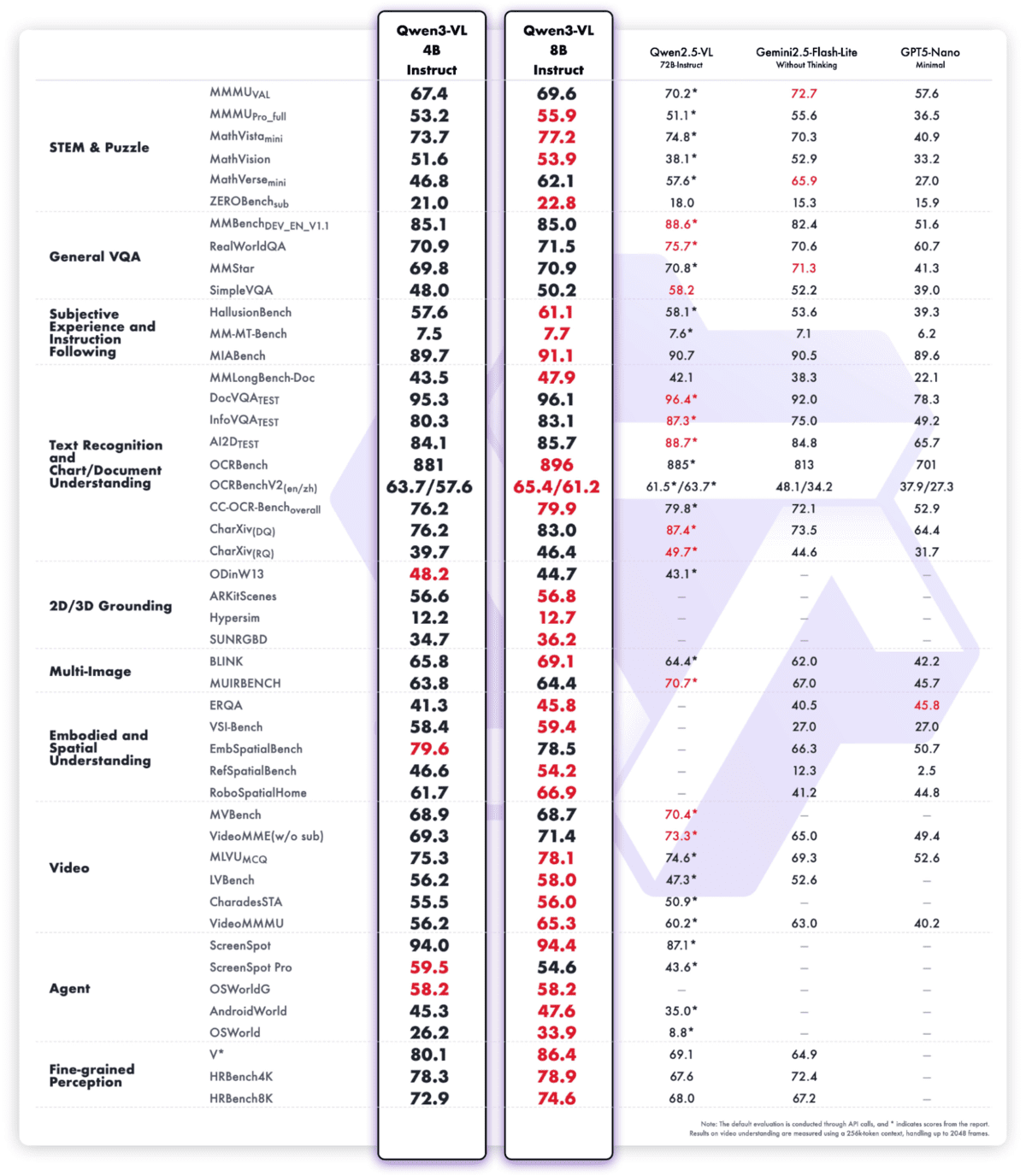
The model supports a native context of 256 KB (expandable to 1 MB), enabling processing of entire books or hours of videos with true recall and precise temporal indexing. Architectural improvements such as Interleaved-MRoPE, DeepStack visual fusion, and precise timestamped text alignment significantly improve long-horizon video inference, fine detail recognition, and image-text grounding
Beyond perception, Qwen3‑VL‑4B‑Instruct acts as a visual agent, capable of handling desktop and mobile graphical user interfaces, invoking tools, generating visual code (HTML/CSS/JS, Draw.io), and supporting sophisticated, multimodal workflows with both text- and vision-based reasoning.
# 3. Exaone 4.0 1.2B
EXAONE 4.0 1.2B is a compact, device-friendly language model designed to bring agentic AI and hybrid reasoning to extremely resource-efficient deployments. It integrates both a no-reasoning mode for brisk, actionable answers and an optional reasoning mode for solving sophisticated problems, allowing developers to dynamically trade off speed and depth within a single model.
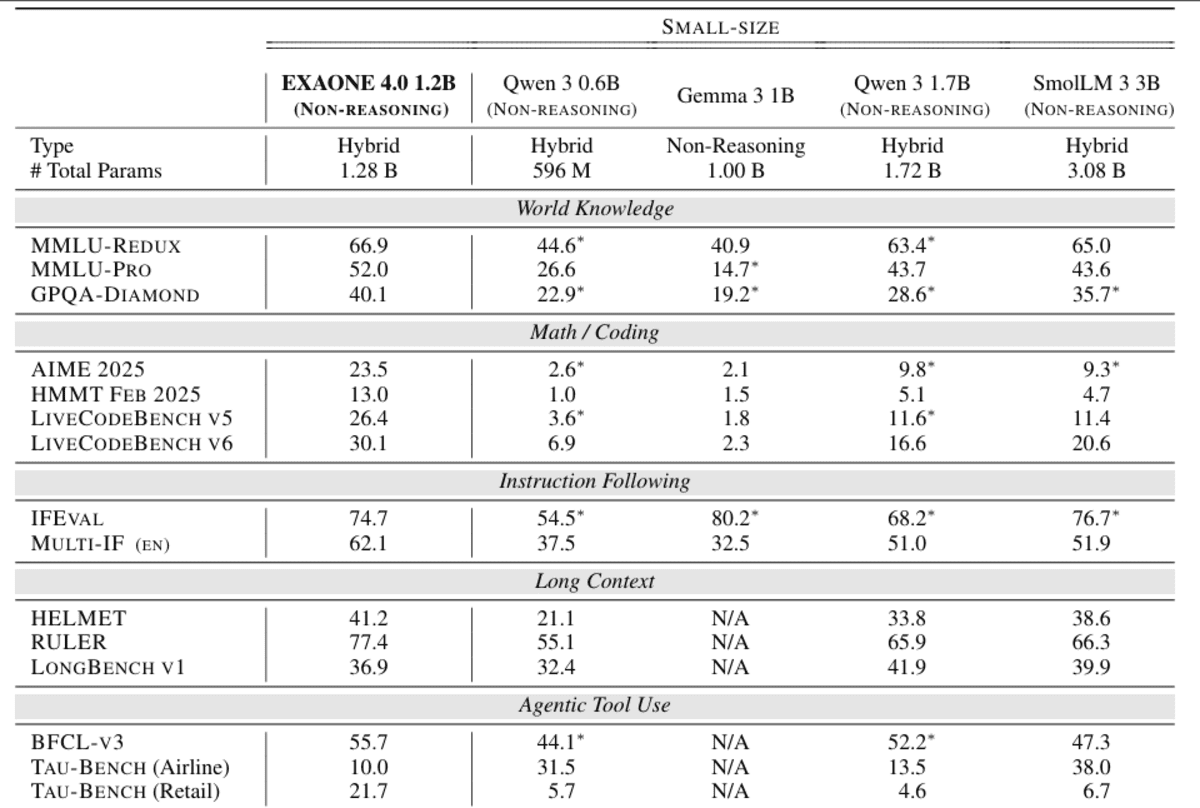
Despite its petite size, the 1.2B variant supports agent-based tools, enabling function calls and autonomous task execution, and offers multilingual capabilities in English, Korean and Spanish, extending its usability beyond monolingual edge applications.
Architecturally, it inherits EXAONE 4.0 advances such as hybrid attention and improved normalization schemes, while supporting a token context length of 64 KB, making it extremely powerful in understanding long context at this scale
Optimized for performance, it is clearly geared towards on-device and low-cost inference scenarios where memory consumption and latency are as crucial as model quality.
# 4. Minister 3B
Ministral-3-3B-Instruct-2512 is the smallest member of the Ministral 3 family and a high-performance petite multimodal language model, built specifically for edge and low-resource deployments. It is an FP8 instruction-specific model, optimized specifically for chat and instruction execution workloads, while maintaining strict compliance with system prompts and structured results
Architecturally, it combines a 3.4B language model with a 0.4B vision encoder, enabling native image understanding along with text reasoning.

Despite its petite size, the model supports a huge 256KB context window, stalwart multilingualism in dozens of languages, and native agent features such as function calling and JSON output, making it ideal for real-time, embedded, and distributed AI systems.
Designed to fit into FP8’s 8GB of VRAM (and even less for quantization), the Ministral 3 3B Instruct delivers high performance per watt and dollar for production applications that demand performance without sacrificing capability
# 5. Jamba’s reasoning 3B
Jamba-Reasoning-3B is a compact yet exceptionally powerful 3 billion parameter inference model designed to deliver high intelligence, long context processing, and high performance in a petite footprint.
A hallmark innovation is the hybrid Transformer-Mamba architecture, in which a petite number of attention layers capture sophisticated relationships, while most layers apply Mamba state space models for highly capable sequence processing.

This design dramatically reduces memory overhead and improves throughput, allowing the model to run smoothly on laptops, GPUs, and even mobile devices without sacrificing quality.
Despite its size, Jamba Reasoning 3B supports 256k token contexts, scaling to very long documents without the need for huge attention caches, making reasoning from long contexts practical and cost-effective
In intelligence benchmarks, it outperforms comparable petite models such as the Gemma 3 4B and Llama 3.2 3B in its multi-assessment composite score, demonstrating extremely high reasoning ability in its class.
# 6. Granite 4.0 Micro
Granite-4.0-micro is a long context instruction model consisting of 3B parameters, developed by the IBM Granite team and designed specifically for enterprise-class assistants and agentic workflows.
Refined on Granite-4.0-Micro-Base using a combination of open permissioned datasets and high-quality synthetic data, it emphasizes reliable adherence to instructions, a professional tone and secure responses, reinforced by the default system prompt added in the October 2025 update.
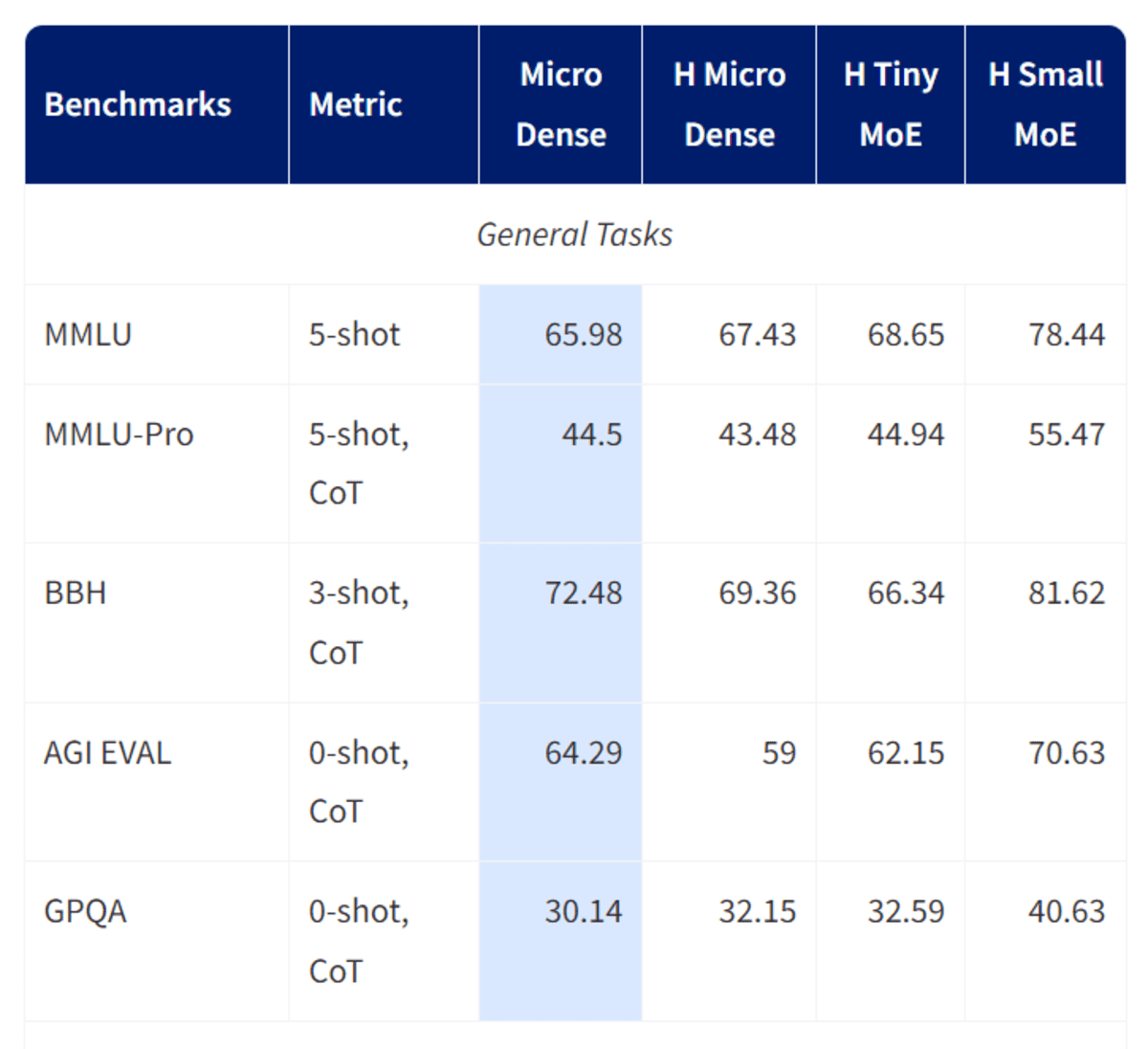
The model supports a very huge 128KB context window, extensive tool invocation and function execution capabilities, and extensive multilingual support covering the major languages of Europe, the Middle East, and East Asia.
Built on a dense, decoder-only transformer architecture and with newfangled components such as GQA, RoPE, SwiGLU MLP, and RMSNorm, Granite-4.0-Micro balances robustness and performance, making it perfect as a base model for business applications, RAG pipelines, coding workloads, and LLM agents that need to integrate seamlessly with external systems under the Apache 2.0 open source license.
# 7. Phi-4 Co
Phi-4 mini-manual is a lightweight, open 3.8B language model from Microsoft, designed to provide capable inference and execution of instructions with low memory and computation constraints.
Built on Transformer’s dense decoder architecture, it is trained primarily on high-quality, textbook-like synthetic data and carefully filtered public sources, with a conscious emphasis on reasoning-rich content rather than raw fact memorization.
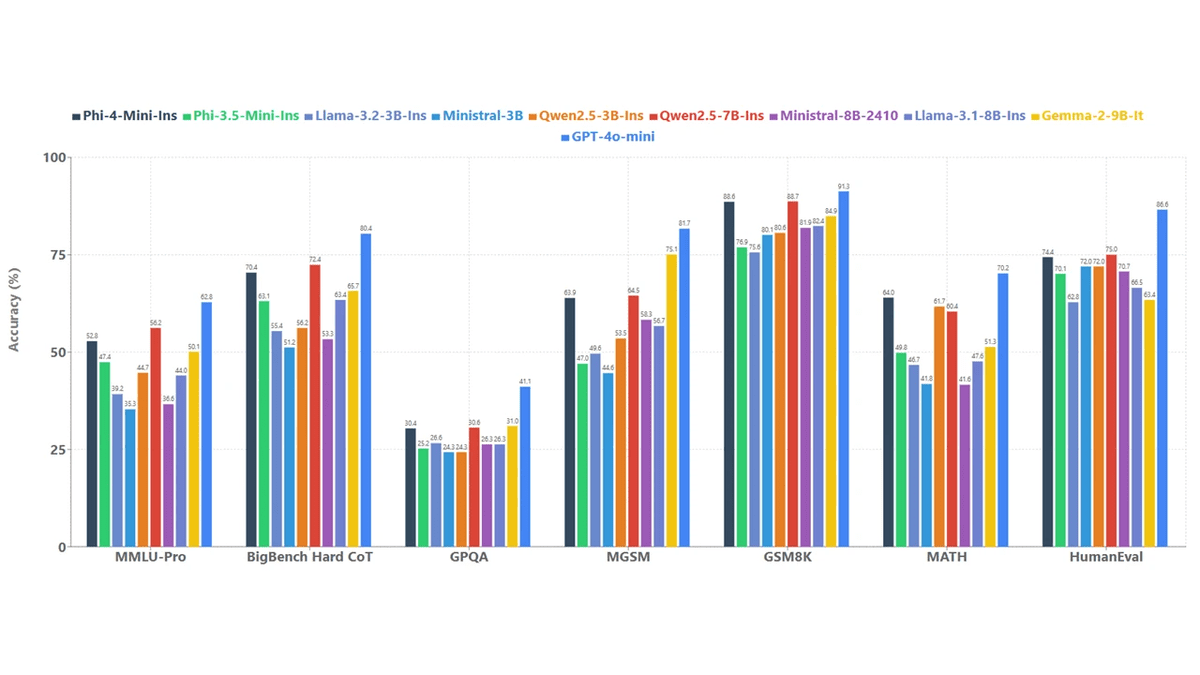
The model supports a 128K token context window, enabling understanding of long documents and longer conversations rarely seen at this scale.
Post-training combines supervised tuning and direct preference optimization, resulting in precise adherence to instructions, reliable safety behavior, and capable function invocation.
Thanks to a huge vocabulary of 200,000 tokens and broad multilingual coverage Phi-4-mini-instruct is a practical building block for research and production systems that must balance latency, cost and quality of reasoning, especially in environments with circumscribed memory or processing power.
# Final thoughts
Overall, many of these models are impressive, but if your priorities are speed, accuracy, and tool calling, the Qwen 3 LLM and VLM variants will be difficult to beat. They clearly demonstrate how far petite on-device AI has come and why local inference on petite hardware is no longer a compromise.
Abid Ali Awan (@1abidaliawan) is a certified data science professional who loves building machine learning models. Currently, he focuses on creating content and writing technical blogs about machine learning and data science technologies. Abid holds a Master’s degree in Technology Management and a Bachelor’s degree in Telecommunications Engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.